



Transforming the Early Detection of Pancreatic Cancers
Or what deep learning and pancreatic cancers have in common

Note: If this post appears truncated or clipped, please click on its title and read it directly on the Substack website. Some email providers may truncate longer messages.

Today’s post is about the wonders of deep learning.
Instead of starting off with the promise though, let’s first address the skepticism: some researchers remain skeptical about the applications of deep learning in life sciences. One of the main reasons for their skepticism is the hype surrounding deep learning.
Hype can indeed be a non-optimal ingredient in the scientific mix, as it sometimes comes at the cost of:
decreased rigor (people rush to use trendy techniques as these can lead to fast publications)
shifting of focus from questions with high future discovery potential to questions with seemingly immediate returns
In this post however, we do not care about the philosophical hype surrounding deep learning. What we are discussing instead is a scenario (a newly published study) in which deep learning is providing a real solution to a real problem.
1. Context & Significance
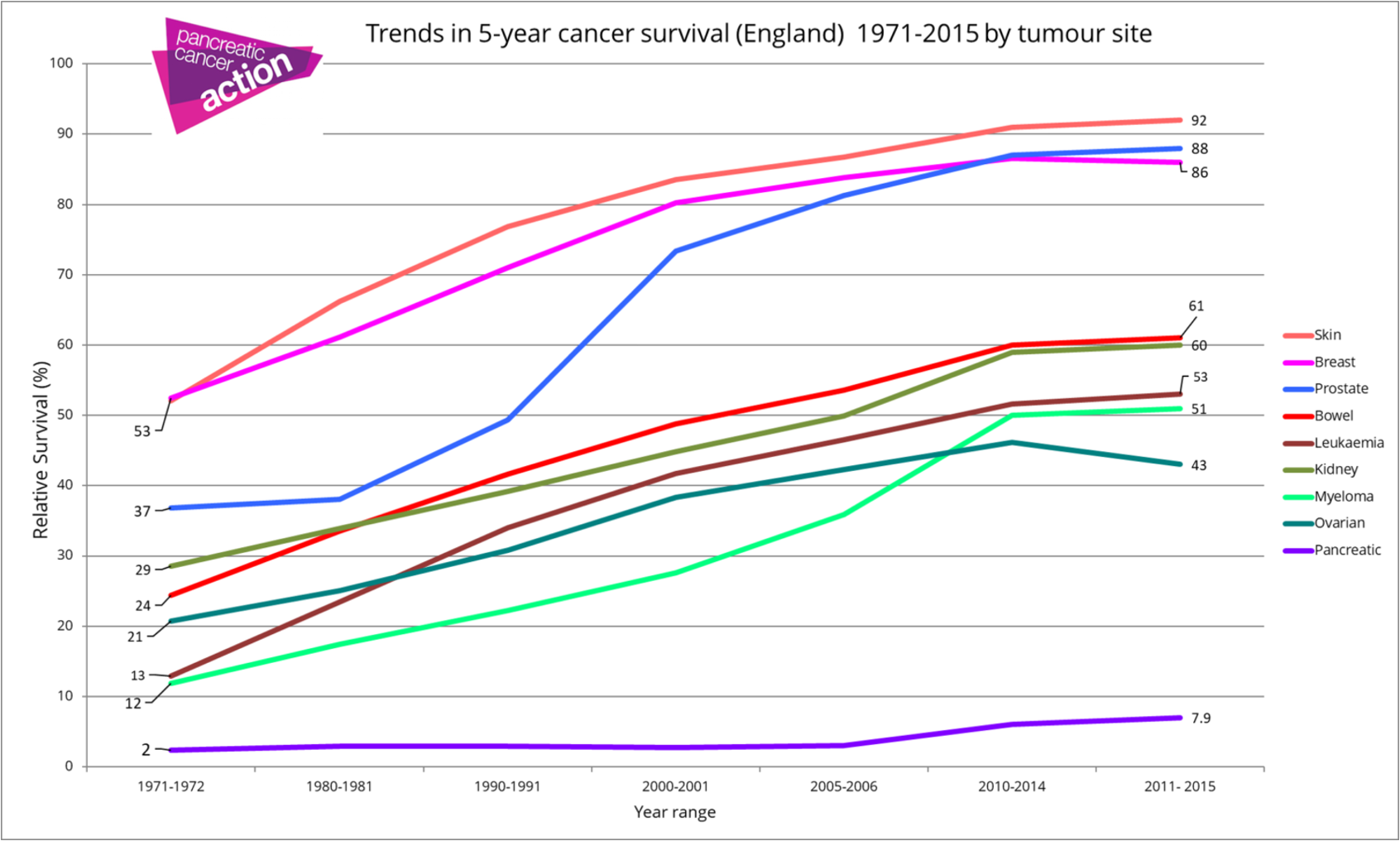
Pancreatic cancer is a terrible disease, usually diagnosed very late. Despite it being a rare cancer type (current incidence estimate is 13 yearly new cases per every 100,000 people in the US), the survival rate from pancreatic cancer is very low (Figure 1).

This is particularly evident when compared with other cancer types, among which pancreatic cancer is an unlucky outlier. Figure 2 illustrates this point quite well (even though the data refers to England only, it stops in 2015, and it lumps all pancreatic cancer stages together).
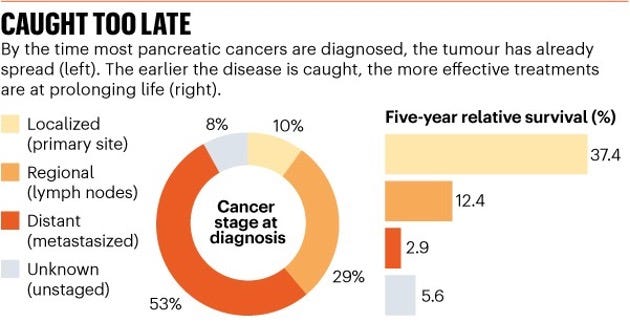
But there’s an important catch: some of the patients who are diagnosed very early can be cured. Not all, but some. Most pancreatic cancer patients are however diagnosed late, with locally advanced or metastatic disease (Figure 3). Important to keep into account though that longer survival times when diagnosed early can also be caused by the lead time bias (it’s all so complicated).
Now we are ready to ask one of the toughest questions out there: given an early tumor, can we tell whether it is curable? The answer is unfortunately a loud and clear no.
Here, I want to take a small detour and reflect on the philosophy of early detection (I also discuss this in a previous post: Why we can't yet cure cancer). Early detection means finding tumors early on. Or, better said, earlier than the time by which they are symptomatic. Such early-identified lesions represent a novel class of tumors: some that we hadn’t studied so far.
How should we approach these tumors? Should we treat them in the same way as we treat tumors currently: surgery, radiation, chemotherapy, targeted therapy, immunotherapy? This sounds like a very reasonable thing to try. But is this the only way, or is it the right way?
You might wonder: why does this matter?
To understand this, we can use a metaphor. Let’s think of tumors as animals (snails, turtles, rabbits, birds) living in a space which is surrounded by a fence. The fence is early detection (Figure 4). Snails and turtles are very slow, and, in our metaphor, they correspond to cancers that either never progress (snails), or progress slowly enough that their evolution doesn’t pose a major health risk (turtles). For snails and turtles, the fence is not necessary. Some other cancers (rabbits) might indeed progress both slow and fast enough, such that their detection is relevant, and treating them early on does improve survival. In our metaphor, the fence will actively keep rabbits from escaping. The worse class of tumors are the birds: tumors that grow so fast that, no matter the strength of the measures (the height of the fence), they will be lethal.

But, as Figure 3 shows, what we do know for sure is that: in order to stand the chance of being cured, it is essential to catch the disease early. Welcome to the concept of early detection (Figure 5).

Now, for catching the disease early, we need some form of screening. But whom to screen? You might think… well, everybody. Unfortunately, such an approach is non-optimal for (at least) these 2 main reasons:
Cost and insurance coverage arguments
For a disease with such a low incidence, the net benefit of screening can be greatly diminished by the false positives of finding the disease when the disease is not there (remember Bayes’ rule)
In other words, we need good ways to prioritize whom to screen. This is exactly the problem that this paper is addressing:
Given a large population (and their clinical records), and given the willingness to screen some people, how do we choose which people to screen such as to identify as many pancreatic cancers cases as possible in a given time interval?
2. Datasets
To understand how this method works, we need to first understand the data it is based on: clinical records. How does this data type look like?
Every time a person goes to the doctor, and they receive a diagnosis, the respective diagnosis is added to their clinical record. These diagnoses follow sequentially over time starting at the beginning of the recording history, one after the other. Across tens of years, they represent the temporal medical history of the patient. The assumption underlying this paper is that, across a large population, the set of temporal medical events trajectories is informative for future diagnoses.
But which exactly is the rule of information flow here? Well, this is something that we don’t know. But what we do know is that this rule is complex.
Too complex.
Put differently, complex enough that effective rule-based screening algorithms based on past and recent diagnoses do not exist.
This is an ideal scenario with lots of data for deep learning to mine. For this reason, several deep learning models have been designed and used successfully to assess and predict the risk of various health outcomes from large clinical records datasets. What this model brings to the table is explicitly using the longitudinal nature of clinical records, i.e., the temporal sequence of codes. This sequentiality might be particularly informative for predictive risk assessment in incremental time intervals.
Let’s discuss in more detail about how this is achieved.
The paper analyzes 2 large datasets of disease codes:
6.2 million longitudinal patient records in Denmark (24,000 pancreatic cancer cases), collected between 1977 and 2018 (Danish Public Health Registry, DNPR)
3 million longitudinal patient records (3,900 pancreatic cancers) in the United States, collected between 1999 and 2020 (US Veteran Affairs, US-VA)
These two datasets are inherently quite different, which makes for an interesting comparison (Figure 6):

the Danish dataset is general (representative of the population of an entire country), while the US Veterans dataset is specific (representative of a selected sub-population with unique characteristics)
medical practice, billing and reporting are very different in Denmark vs. the US: the health records in the US Veterans dataset have shorter, but much denser disease histories than the Danish ones (strikingly, there’s a median of 188 records per patient in the US-VA dataset versus only 22 records per patient in DNPR)
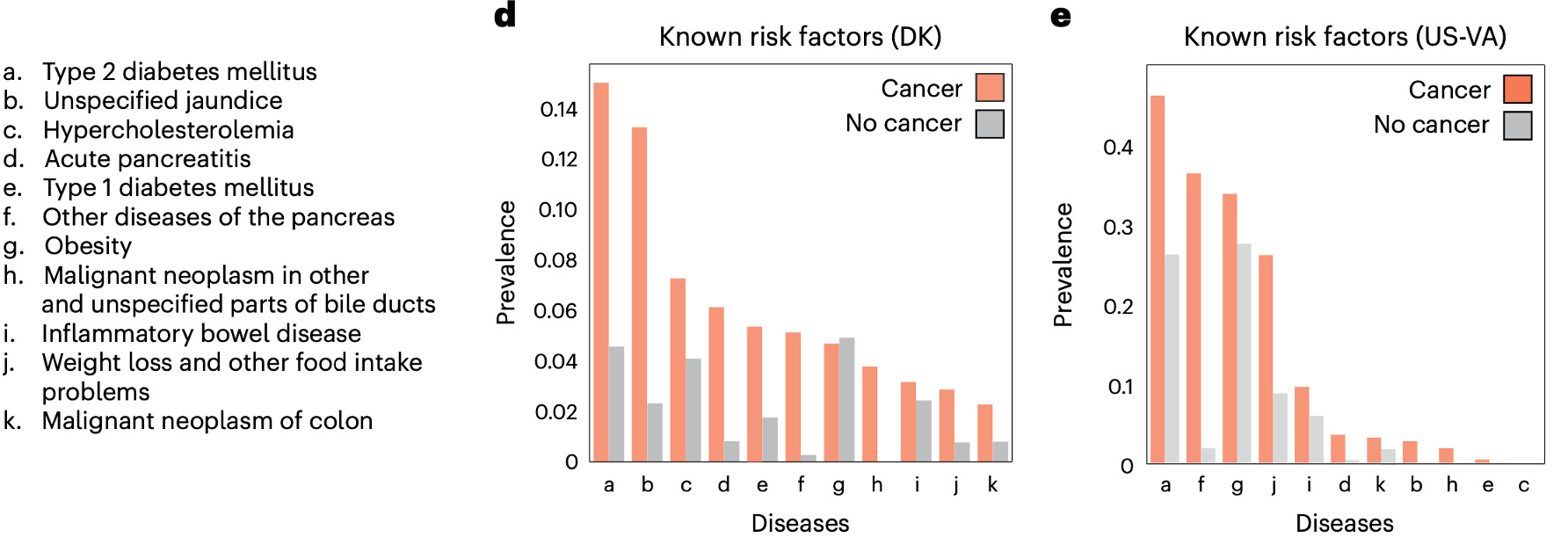
the prevalence of known risk factors for pancreatic cancer is another distinguishing feature of the two datasets. For example, type 2 diabetes, one of the well-known risk factors for a pancreatic cancer diagnosis, occurs in 3 times more patients in the US-VA dataset than in DNPR (Figure 7)
3. Deep learning model
The framework described below is general, and, in this paper, it is applied for training, prediction and performance evaluation on both the Danish and the US Veterans datasets. It can also work in principle for any other clinical records dataset, provided that the disease codes used are relevant and informative.
3.1 Learning
Training is done on 80% of the data (training set). A development set (10%) is used to examine the performance for different hyperparameter settings and for model selection. Lastly, a fully withheld test set (10%) is used to evaluate the performance of the selected models (Figure 8, left).

The training data contributed by each patient consists of the temporal sequence of diagnostic codes for that patient, which we call the clinical diagnosis trajectory. This trajectory includes both disease codes corresponding to diagnoses, as well as timestamps indicating when these diagnoses were received.
Inspired by Natural Language Processing (NLP) training frameworks, the model is trained with augmented data for each patient, by considering all partial trajectories (of length at least 5) of disease codes. Therefore, multiple trajectories enter the training dataset for each patient, and each trajectory is incrementally larger than the previous one with the next disease code, in a temporal sequence (Figure 8, middle).
For cancer patients, only trajectories that end before a cancer diagnosis is received are included. For patients without a pancreatic cancer diagnosis, only trajectories ending earlier than 2 years before the end of disease records are included, in order to avoid potential undiagnosed future cancers that would bias the accuracy of the prediction labels.
Now, the timepoint at which clinical records (or available disease history) end is called the time of assessment. The metric to be optimized by the model is the probability of being diagnosed with pancreatic cancer at different time intervals after the time of assessment (3 months, 6 months, 12, 36, 60 months; Figure 9). In other words: what is the chance of a pancreatic cancer diagnosis in the next 3 months after the available disease history ends? How about in the next 6? How about 12, 36, or 60?

3.2 Architecture
The model consists of 3 stages (Figure 10):

embedding of the categorical disease features (level-3 ICD codes) onto a continuous low-dimensional latent space.
encoding the temporal sequences of diagnostic codes into feature vectors using either sequential layers (GRUs - gated recurrent units), attention layers (Transformers) or pooling layers (MLP - multilayer perceptron and a control bag-of-words model, which ignores the time and order of disease events). The encoding layer also includes age.
predicting time-dependent cancer risk, in the form of an estimated probability of pancreatic cancer diagnosis, following a given disease history. The parameters of the model are optimized by minimizing the prediction error: the difference between estimated risk and real outcome, encoded as a step function (0 before the diagnosis was received, and 1 afterwards), via a cross-entropy loss function. The loss function is averaged over the 5 time-intervals considered for prediction (Figure 10).
Further, some of the patients are prioritized as high risk, by using a threshold on the estimated risk. These are the patients which are proposed for surveillance and additional follow-up investigations (Figure 11).

3.3 Evaluation
Model evaluation is done separately for each time prediction interval. The following example given in the paper is quite intuitive as to what this means in practice:
“Consider the prediction score for a particular trajectory at the end of the 3-year prediction interval.
If the score is above the threshold, one has a correct positive prediction if cancer has occurred at any time within 3 years and a false-positive prediction if cancer has not occurred within 3 years.
If the score is below the threshold, one has a false-negative prediction if cancer has occurred at any time within 3 years and a true-negative prediction if cancer has not occurred within 3 years.”
The 4 tested modeling architectures (GRU, Transformers, MLP, bag-of-words) were assessed by 2 methods:
AUROC: the area under the receiver operator characteristic curve
Relative risk (RR) curve, quantifying by which factor a prediction method does better than a random pick based on the population disease incidence alone
\(RR = \frac{\text{precision}}{\text{incidence}} = \frac{TP/(TP+FP)}{(TP + FN) / (TP + FP + TN + FN)}\)
For a realistic clinical implementation, the paper proposes advancing to a screening program the top 1,000 patients predicted to be at highest risk of developing pancreatic cancer in a given time interval.
4. Model performance
4.1 Danish data
Among the 4 modeling architectures tested, Transformers showed the best performance, with a particularly impressive RR ratio (Figure 12, Danish data). It is nevertheless interesting how the AUROC performance of the various architectures is not that much different, including the control bag-of-words approach, which ignores the sequentiality of the disease codes.

For assessing model performance more thoroughly, the paper sets up multiple in silico relevant experiments, such as:
excluding from training the disease history events occurring in the period right before a pancreatic cancer diagnosis (3, 6 or 12 months before). There are two reasons why such a sensitivity analysis is relevant. First, these disease codes (unlike the others) may indirectly, but strongly, already cover the pancreatic cancer label, which may bias the predictions. What’s more, these diagnoses can lead physicians to suspect pancreatic cancer, without the need to rely on black-box algorithms. Outcome: as expected, the model without any exclusion performs much better. This means that the medical events happening closer to a pancreatic cancer diagnosis are highly relevant in predicting the disease.
taking into account only risk factors (disease codes) already known to increase pancreatic cancer risk, as opposed to the entire medical history. Outcome: the model trained on all disease codes performs much better (Figure 13). This result is one of the key points of the paper, and one of the strongest arguments in favor of the deep learning approach employed: using only the diagnoses that we currently think are informative is not enough, and additional information is extracted from the stuff we would not have normally considered relevant.
assessing how the prediction performance changes with different time prediction intervals. Outcome: as expected, the shorter the time prediction interval after the end of disease history, the better the performance of the model. This is because longer time intervals imply larger gaps in potentially informative medical information.

4.2 Cross-application
The impressive prediction performance discussed above comes from a model trained on a very large corpus of well-curated clinical data (remember, the Danish dataset had 6.2 million patient records, see Figure 6). Putting together such a high amount of high-quality data is prohibitive for many healthcare settings (at least nowadays). Therefore, a very relevant aspect to investigate is how applicable is this pre-trained model in a different healthcare setting?
Luckily, we can address part of this important question here, by applying the Danish-trained model on the US Veterans data, and the US Veterans-trained model on the Danish data! As discussed above in Section 2 (Figures 6 and 7), the two datasets are inherently quite different in several conceptual ways, therefore our prior expectation could be that cross-applying them would lead to substantial decreases in performance.
Let’s see whether this is true.
The Danish-trained model was cross-applied without any changes to its architecture on the US Veterans dataset (after only mapping the codes from one healthcare system to the other). As expected, its performance dropped substantially (Figure 14 a vs. b).
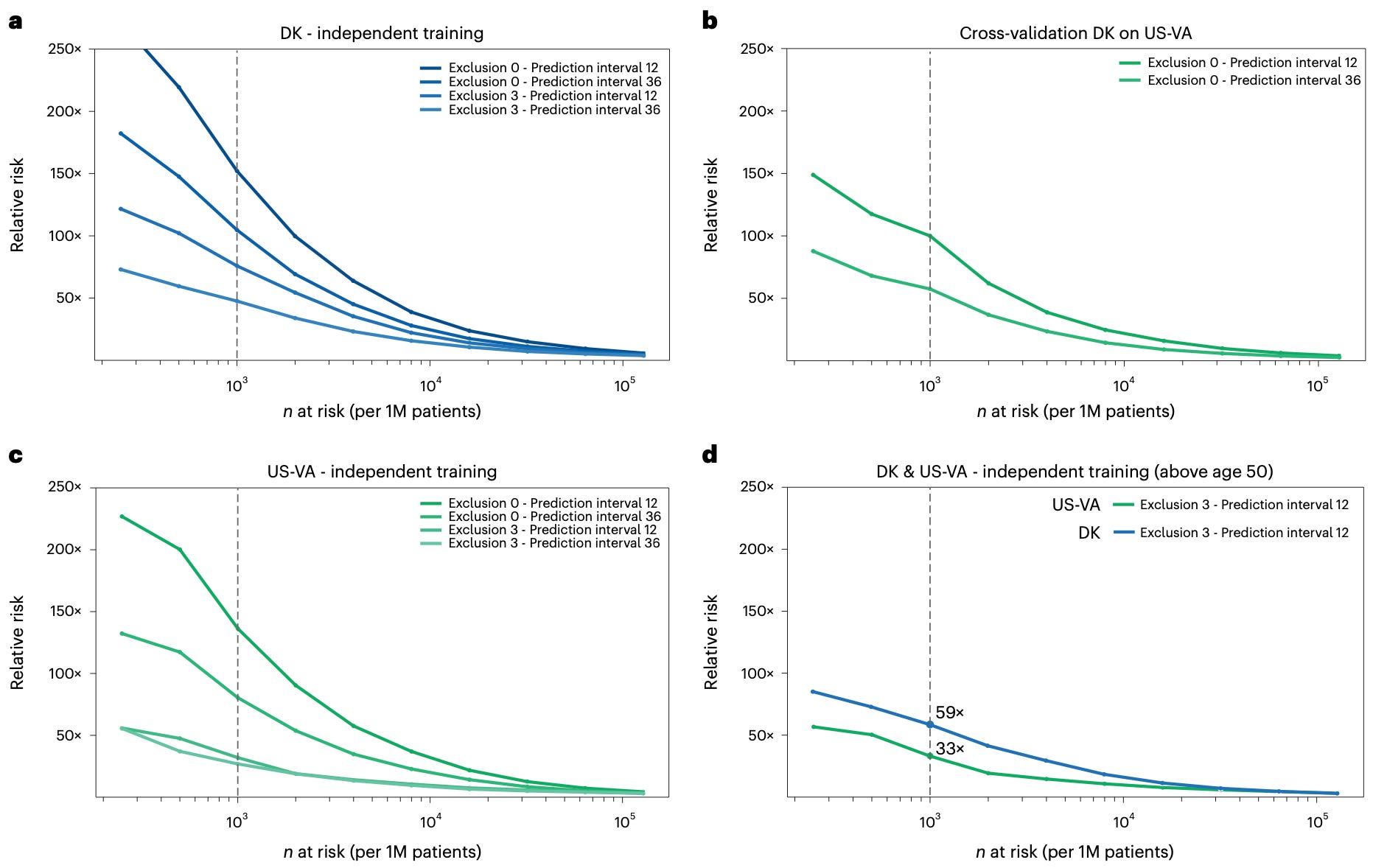
But how does the same model look like when trained and applied on the US-Veterans dataset alone? Indeed, prediction performance is again high (Figure 14c, compare with panel b), confirming that, when trained on a dataset with the exact same structure as the one used for prediction, the model does generalize well.
To drive home the point of a realistically-implementable clinical surveillance program, the paper identifies the top 1,000 patients (per every 1 million people) at highest risk of developing pancreatic cancer in a 12 months’ time prediction interval, with 3 months data exclusion (Figure 14d). The relative risk ratio guarantee is impressive: the patients proposed for follow-up are at least 59 times (Danish data) and 33 times (US-VA data) more likely to be diagnosed with pancreatic cancer in the following year than a totally non-informative prediction (disease incidence alone).
5. Feature interpretability
Lastly, the paper also addresses some aspects of feature interpretability, a key concern with deep learning medical applications. We would of course prefer that any method or tool we ever apply in a medical setting is fully interpretable, such that we, humans, can always justify and track why the model predicts what it does. In this setting, we would really want to know which diagnoses are most indicative of pancreatic cancer risk?
Even though deep learning models are generally far less interpretable than more explicit modeling approaches, there are lots of active research directions that aim to reliably map deep learning reasoning to human-interpretable steps.
Integrated gradients is one such interpretability approach to estimate feature attribution: how much each input feature contributes to predicting outcome. Here, the attribution of each feature is estimated by cumulating its gradients along all trajectory points from input to the baseline, summed up across all trajectories for pancreatic cancer patients.
For each time prediction interval, the input features with highest total attribution scores represent the diagnosis codes with highest (isolated) associations with pancreatic cancer (Figure 15). Even though these top codes are hardly informative by themselves, they are nevertheless interesting to interpret, especially by comparing their contribution to prediction across the different time prediction intervals (early cancers vs. late cancers).

As expected, most of these codes are no strangers to clinical practice. Some codes are quite specific (e.g., “non-insulin dependent diabetes mellitus”), while others are very general (e.g., “medical observation and evaluation for suspected diseases and conditions”). For trajectories that end closer to cancer diagnosis (0-6 and 6-12 months), the top features are directly related to pancreatic cancer, whereas for cancers diagnosed later, the top features can represent early sign of the disease (if only they were more specific!).
One interesting example is type 2 diabetes, a well-known risk factor for pancreatic cancer (see also Figure 7). In the Danish dataset (Figure 15 b), the importance of non-insulin dependent type 2 diabetes in predicting pancreatic cancer decreases with getting closer and closer to the pancreatic cancer diagnosis. Such temporal patterns of feature attribution among early and late cancers could indicate causal or mechanistic roles for selected diagnostic codes (causal as they are most important longer time before diagnosis). This is in stark contrast with “unspecified jaundice” for example, which is a known clinical occurrence closely preceding a pancreatic cancer diagnosis.
5. Thoughts
So, what do deep learning and pancreatic cancers have in common? This study shows how deep learning provides a feasible and actionable solution to a real clinical problem that will likely improve pancreatic cancer survival: early detection of pancreatic cancers. That’s why this paper is so important.
Predicting health outcomes (in this case, a pancreatic cancer diagnosis) from health records has historically been one of the most fruitful use-cases of deep learning in the medical domain, as large volumes of health records data already exist and are straight-forward to mine. However, one of the main criticisms of this type of learning is that the insights obtained are often not clinically actionable. This criticism doesn’t hold true for the present paper.
From a modeling perspective, explicitly encoding the temporal dependencies among disease codes (rather than using them without this information) helps to improve the predictive model, and is something that most previous models do not attempt. What’s more, applying Transformers to trajectories of disease codes, and thinking of disease codes in medical history as “words in sentences” is appealing.
One of the most interesting results is comparing performance when all disease codes are included into the model (better), versus when only known pancreatic cancer risk factors are considered. This shows that (at least some of) the medical history that we would have likely labeled as un-informative is in fact informative to a certain extent. It also shows that the predictive relation between disease codes and pancreatic cancer diagnosis is something that we cannot yet understand and explicitly model.
Obvious open questions and future directions include:
How about predicting other diagnoses except pancreatic cancer? The proposed deep learning framework is general enough to allow this, as no explicit pancreatic cancer domain knowledge goes into the architecture of the model. This question can therefore be answered right away.
How would such a model perform in other healthcare settings, except the two presented in this paper? To answer this, a large corpus of training data from a new healthcare setting would need to be available. Nurses Health Study might be a suitable use-case to answer this.
All that being said, we have many reasons to be extremely excited and hopeful about the future (Figure 16). Disease codes represent not only a specific data type, but also a biased one. Disease codes are medical diagnoses, the large majority of which are generated rather indirectly, as the consequence of an external process: the person was not feeling well, hence they went to the doctor. In other words, diagnoses are only a narrow and specific window into the intricate workings of living humans. Most of the complexity of living remains largely untapped, with an immense potential to be discovered and utilized.
Such modeling frameworks as the one discussed in this post can be enhanced in several ways with complementary data types, which, in my opinion, hold a true potential to boost prediction accuracy to levels we cannot even imagine.
For example: how about integrating the bloodwork values from regular check-ups (most of which represent unbiased sampling) into this prediction model?
How about data on heart rate, cardio fitness, or sleep quality, which are continuously recorded by wearables nowadays?
How about glucose values from continuous glucose monitors?
Even though this perfect multi-modal dataset does not exist today, it will certainly exist at some point in the near future. This is only the beginning of this journey. There is so much about ourselves that we don’t yet know, and so much to discover.

6. Summary
Pancreatic cancer is a disease with poor survival, usually diagnosed very late
Early detection is well positioned to make a difference in pancreatic cancer survival, provided that high-risk people can be identified for screening and surveillance before being diagnosed with the disease
This study proposes a deep learning method to predict the risk of pancreatic cancer occurrence based on longitudinal sequences of disease codes (temporal patient clinical records)
The method is applied on two large datasets: the Danish Public Health Registry data (6.2 million patients) and the US-Veterans data (3 million patients)
Transformers is the best-performing modeling architecture
Performance is higher when using the entire patient medical history, as compared to only disease codes previously known to be associated with pancreatic cancer. This indicates that seemingly uninformative medical events do in fact hold predictive information
Based on this methodology, a realistic and clinically-implementable surveillance program would propose for follow-up patients at least 59 times (Danish data) and 33 times (US Veterans data) more likely to be diagnosed with pancreatic cancer in the following year than a non-informative prediction based on disease incidence alone
Lots of open questions and exciting avenues for improving prediction and future discoveries